Using the Elsevier APIs for IR/CRIS/VIVO
1 Introduction
One of the most common uses of Scopus data outside of the Scopus user interface (www.scopus.com) is that of institutional repositories and current research information systems. An Institutional Repository (IR) is a system for collecting, preserving, disseminating and promoting the intellectual output of an institution electronically. Roughly 80% of all universities worldwide have some sort of IR. The size and complexity of an IR can vary and is typically dependent on the institution's level of investment. A Current Research Information System (CRIS) is a database or other information system for storing data on current research by organizations and people, usually through some kind of project activity, financed by a funding program. CRIS databases are often connected to Institutional Repositories, whereby the CRIS system handles internal data aggregation and analysis, and the IR promotes externally what the organization is doing in terms of research and teaching. Also part of this landscape is VIVO (http://vivoweb.org/), an open-source tool for the discovery of researchers across institutions that has similar capabilities for showcasing universities, researchers and their output. A major challenge for the managers of systems like this is making sure that all of the institute's research output is, indeed, captured. Universities are large, relatively loosely organized organizations, and researchers and research groups often work rather independently. This makes it hard for an IR/CRIS/VIVO manager to keep track of all the material that is written and published by an institution's collective staff and faculty. Scopus can help meet that challenge. As an abstracting and indexing database, it captures articles being published in virtually all scholarly journals of any significance in the world; and its profiling of authors and institutions makes it easy to find new articles by those authors at those institutions. The Scopus user interface offers many features to that end, allowing administrators to manually find publications originating from their institution that they can then add to their system. Similarly, the Elsevier RESTful APIs allow access to Scopus data to allow developers working on IRs/CRISs/VIVO installations to write programs that automatically extract data from Scopus periodically, and add that data to their systems. The Scopus data that is available for use in IRs, CRISes and VIVO is primarily publication metadata, and their use is subject to the content use policies outlined [[here]]. In addition, working with the APIs requires some insight into our data model to better understand how to extract the information you require.
2.1 Some basics
The Scopus data model is designed around the notion that articles are written by authors that are affiliated with institutions.
Visually and rather simplistically, this relational model can be represented like this:
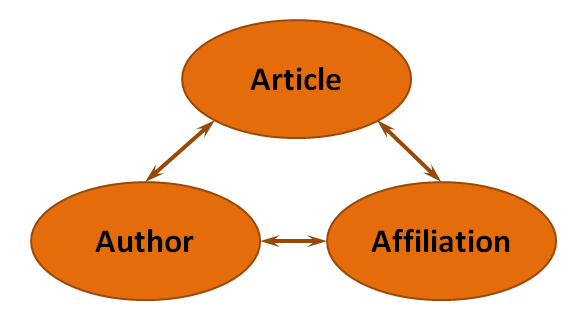
Scopus has different types of records for each of these:
- Article records - e.g. https://www.scopus.com/record/display.uri?eid=2-s2.0-0035234193&origin=resultslist
- Author profiles - e.g. https://www.scopus.com/authid/detail.uri?authorId=7202909704
- Affiliation profiles - e.g. https://www.scopus.com/affil/profile.uri?afid=60002573
Each of those record types has a lot of metadata associated with it (e.g. the keywords of an article, the publication range of an author,
the address of an institution), and some calculated metrics (such as h-index, citation count, publication count, etc.).
2.2 Linking to Scopus
As outlined in the terms of use, we require that your IR/CRIS/VIVO pages show links to Scopus where appropriate.
Specifically, you should display links in your IR as follows:
- each document records that contains metadata from Scopus, should have a link to that document's page on Scopus
- any document citation count should link back to the cited-by list for that document on Scopus
- any author page that is linked with a Scopus author ID should be linked to that author's profile on Scopus
The URLs for these Scopus pages are returned by our APIs. The pages they lead to are fully functional Scopus pages with all bells
and whistles if Scopus recognizes the incoming user as a licensed Scopus user. If Scopus does not recognize the user as being licensed,
it will show a free preview page with data, but without any broader Scopus functionality.
3 Querying the APIs
This section describes how the content APIs can be used specifically for populating an IR and keeping it up-to-date.
In order to work with the content APIs, you'll need an APIKey:
- First, review the section on Authentication to get a better understanding of the authentication process.
- Second, review the IR/CRIS policy.
- Third, self-register for an API-Key here.
3.1 Searching for documents for your institution
This section provides a good strategy that can be used to discover all documents written by authors at your institution to-date, and how your system can stay up-to-date with new publications.
3.1.1 Initial "dump"
The best way to find out what the affiliation ID of your institution is, is by using Scopus' affiliation search:
https://www.scopus.com/search/form.uri?display=affiliationLookup&clear=t
You can search there for affiliation by name, and browse through results. It may very well be that you will find multiple affiliation IDs
that are relevant to you: for instance, the medical center of a university will likely have a different affiliation ID than the university itself.
In those cases, you can take all affiliation IDs and use them in one single request using an 'OR' operator:
http://api.elsevier.com/content/search/scopus?query=af-id(60032114)+OR+af-id(60022265)
We get around this limit using our retrieval APIs for author or affiliation,
and the 'DOCUMENTS' for author view and affiliation view.
For example, consider the following request:
http://api.elsevier.com/content/affiliation/affiliation_id/60008134?start=1&count=25&view=DOCUMENTS
<?xml version="1.0" encoding="UTF-8"?> <affiliation-retrieval-response xmlns:xoe="http://www.elsevier.com/xml/xoe/dtd" xmlns:xocs="http://www.elsevier.com/xml/xocs/dtd" xmlns:prism="http://prismstandard.org/namespaces/basic/2.0/" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:cto="http://www.elsevier.com/xml/cto/dtd" xmlns:ce="http://www.elsevier.com/xml/ani/common" xmlns:ait="http://www.elsevier.com/xml/ani/ait"> <coredata> <prism:url>http://api.elsevier.com/content/affiliation/affiliation_id/60008134</prism:url> <dc:identifier>AFFILIATION_ID:60008134</dc:identifier> </coredata> <documents start="1" count="25" total="128402"> -truncated-The response shows 128402 results associated with this affiliation (CNRS Centre National de la Recherche Scientifique). Noting the
http://api.elsevier.com/content/affiliation/affiliation_id/60008134?count=200&start=0&view=DOCUMENTS
http://api.elsevier.com/content/affiliation/affiliation_id/60008134?count=200&start=200&view=DOCUMENTS
http://api.elsevier.com/content/affiliation/affiliation_id/60008134?count=200&start=400&view=DOCUMENTS
and etc.
You can also do the same with authors, based on their author-id:
http://api.elsevier.com/content/author/author_id/7202762180?start=0&count=200&view=DOCUMENTS
3.1.2 Incremental updates
After the initial extraction, it is much easier to for your IR/CRIS/VIVO to stay up to date with new publications in Scopus: you can query
the API to just return the documents added to Scopus for your institution during a specific period.
For example:
https://api.elsevier.com/content/search/scopus?query=AF-ID(60019702)+AND+orig-load-date+aft+20160530
This query returns the documents for affiliation ID '60019702' that were added to Scopus after 30st of May, 2016.
This is ideal for regular updates to your IR/CRIS.
The ORIG-LOAD-DATE value represents the timestamp of when a record has been loaded to Scopus for the first time. Its format is YYYYMMDD and it can be used with BEF, IS and AFT operators.
Scopus may re-load existing records for various reasons; sometimes for content enhancements or corrections but also in support of functionality changes. The timestamp of when a record was last loaded to Scopus is called LOAD-DATE and it can be used in the same way a original load date.
It is up to you which date you'd like to use for your incremental updates.
3.2 Retrieving all metadata and metrics for each document
The search queries as described in the previous section return core bibliographic records, with only some of the metadata that you are allowed
(per section 2.2) to use in your IR/CRIS/VIVO. However, each record in the search results will also have a 'prism:url' field that contains a
URL like this...:
http://api.elsevier.com/content/abstract/scopus_id/0026592326
... which your system can use to fetch the full Scopus record for the article, and from which you can parse the additional data that you're
allowed to use per our policies.