Support
If you don't find what you need in this FAQ, please contact us through our Elsevier Research Product APIs Support Center
There is a basic SDK available for the RP APIs at ![]() GitHub. Please note this SDK is not supported by Elsevier.
GitHub. Please note this SDK is not supported by Elsevier.
Frequently Asked Questions
Getting Started
Q: What are the Elsevier Research Products APIs?A: APIs (Application Programming Interface) are tools that allow for computer-to-computer interaction. Elsevier Research Products APIs help researchers integrate Elsevier data into their work. Elsevier has APIs available for many of our Products including ScienceDirect, Scopus, Engineering Village, Embase, SciVal and SUSHI.
Q: Who can use the Elsevier Research Products APIs?
A: Various options are available for researchers who want to use Elsevier APIs:
- Non-Commercial Users (Researchers in Academic & Public Sector Institutions, Charities & Charitable Foundations): Most APIs (except SciVal APIs) are available for no charge, for non-commercial use, subject to Elsevier's policies and limits on usage.
- Commercial Users (Researchers in Private Sector & Commercial Institutions): APIs are available (for commercial use), with an API license and subscription, please contact us here to discuss your request
Q: Where can I learn more about a specific set of APIs?
A: API Technical documentation grouped by product is available here. In addition, review our step-by-step technical guides. Each guide walks you through the typical technical approach for a given use case, explaining which API calls need to be made at what point in your application's logic and for what purpose. These steps may need adapted for your particular situation.
Q: How do I start using the Research Products APIs?
First, obtain an API Key. If you do not already have an Elsevier user ID, you will have to register prior to obtaining an API Key. Once you have the API Key, you can start using the APIs. Our step-by-stepp technical guides are available should you require instructions with greater detail.
Q: What are the quotas and throttling rates for the Research Products APIs?
For information about default API settings, quota, and throttling rate limits, refer to our Default API Key Settings documentation.
Q: Where can I get help or report an issue?
Please contact us through our Elsevier Research Product APIs Support Center
Advanced Topics
Q: How can I familiarize myself with the Scopus APIs?A: You can get started by referring to our Getting Started guide for Scopus APIs
Q: I have access to some API resources, but others are returning "unauthorized" or "insufficient privileges" responses. Can this be fixed?
A: Your API key has default settings ; access to some APIs and service levels is enabled by default, while access to others can be enabled manually but require further permissions from Elsevier. Attempts to access features not enabled by default will result in such error responses.
In addition, the data available depends on your institutional subscriptions, and only when you're making calls from within your institutional network are you considered a subscriber. If you attempt to access a subscriber-only feature from home, you're likely to receive such an error response. Elsevier Research Products APIs rely primarily on Institutional IP address for authentication. API access through proxies is not supported, however Elsevier will provide remote access direct to the APIs using a special access credential ("Institutional Token"). If you are working away from your main institutional network or your institution accesses Scopus.com, Scival.com, or ScienceDirect.com through a proxy, please contact us to enquire about Institutional Token access.
If you require access to additional API resources that are not available by default, please contact us through the above link.
Q: How can I obtain a list of articles (cited-by list) that cite the articles of interest to me?
A: The Scopus Search API supports this functionality, but Elsevier limits access only to subscribers and only for specific use cases. If you require use of this feature, please contact us as described in the 'Attention Subscribers' section on the default API key settings page .
A common misconception is that the Citation Overview API provides this functionality. However, this API supplies only article citation values, with or without self-citations, broken down by year. It does not enable you to extract a list of articles that produce those values.
Q: I found authors with multiple author IDs. Can this be fixed?
A: The creation of both author and affiliation profiles is an automated process performed by complex algorithms during content processing. The original data is sourced from thousands of publishers and contains numerous flaws due to translations between languages, differences in naming conventions, varied publishing and data standards, etc. When matching documents to existing profiles, the algorithm takes a conserative approach to avoid misattribution, occasionally resulting in the creation of a new author profile for an existing author. This is a superior approach as it's far easier to analyze and correct duplicate profiles than incorrectly merged profiles.
To address the problem of duplicate profiles, Scopus created Profile Wizards that allow authors and affiliations to correct their profiles directly through the Scopus web interface. The API team isn't involved in the process, but when the corrections are made in the Scopus database, they're immediately reflected in the API response data.
Q: How do I know the exact time when my quota resets each week?
A: Details:
- The quota reset time is specific to each API and is returned as a header in the API response.
- Example header values in the response include:
- X-RateLimit-Limit: "20000"
- X-RateLimit-Remaining: "1227"
- X-RateLimit-Reset: "1692342443"
- These values represent the quota limit, remaining requests, and the reset time respectively.
- The third field, X-RateLimit-Reset, contains a Unix timestamp.
- Users can use a timestamp converter to convert the Unix timestamp to a "regular" date.
- An example should be provided demonstrating the conversion process:
- The Unix timestamp 1692342443 converts to 07:07:23 GMT on Friday, August 18th.
Q: What is the difference between ScienceDirect and Scopus Data?
A: ScienceDirect and Scopus use two different databases.
Details:
- ScienceDirect contains full text articles from journals and books, primarily published by Elsevier but also including some hosted societies.
- Scopus indexes metadata from abstracts and references of thousands of publishers, including but not limited to Elsevier, and builds additional functionality on top of that data: citation matching, various metrics, author profiles, and affiliation profiles. The relationship between articles, authors, and affiliations is explained here.
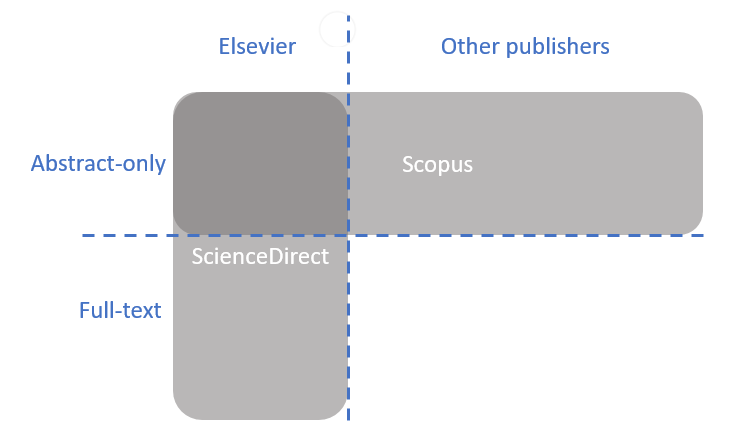
Note that ScienceDirect cannot be searched using Scopus-native identifiers like AF-ID, Scopus ID, etc.
For more information about our content, you can visit the content sections of the Scopus and ScienceDirect product sites:
Q: How do I become a partner?
A: Visit our Partner Support Reference for more info.